This article is reposted from Prefect.io blog, and you can read the original there.
The hardest part about writing a blog is getting started - writing the outline and filling out the first few key points. The same can be said for writing data pipelines: you need to inspect docs, determine data structures, write tests, etc.
What if you could build a resilient, production-ready data pipeline that is scheduled and running in just a few minutes? We’ll show you how to do just that with dlt and Prefect.
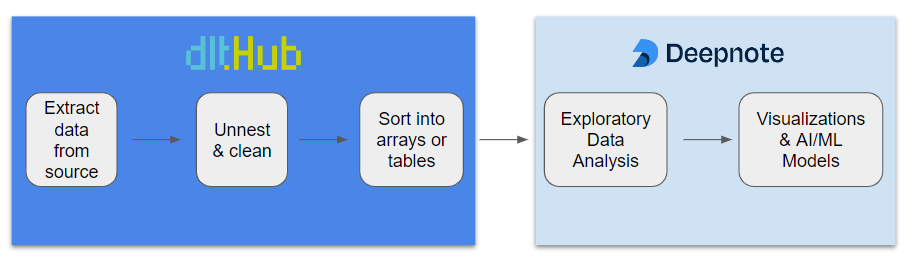
dlt
dlt is an open-source library that you can add to your Python scripts to load data from various and often messy data sources into well-structured, live datasets. It abstracts away the need to hunt through docs, interpret APIs, and reinvent the wheel every time. Instead of writing a custom pipeline, you can use dlt to build a framework for your pipelines for any combination of tools.
Moving Slack data into BigQuery
We use BigQuery as our data warehouse, and try to centralize as much information there as possible. Given our Slack community is over 25,000 people, it makes sense to use that information to better our community. We can identify the types of questions our users struggle with the most, and take action to improve Prefect by using Slack data.
If you Google “load Slack into BigQuery,” you’ll see a bunch of listings for no-code tools like Zapier that can help you move data… for a fee, of course. What if you want to do this yourself? Slack has an API, but check it out. It would take some effort to interpret even a simple response like this one for users:
{
"ok": true,
"members": [
{
"id": "W012A3CDE",
"team_id": "T012AB3C4",
"name": "spengler",
"deleted": false,
"color": "9f69e7",
"real_name": "spengler",
"tz": "America/Los_Angeles",
"tz_label": "Pacific Daylight Time",
"tz_offset": -25200,
"profile": {
"avatar_hash": "ge3b51ca72de",
"status_text": "Print is dead",
"status_emoji": ":books:",
"real_name": "Egon Spengler",
"display_name": "spengler",
"real_name_normalized": "Egon Spengler",
"display_name_normalized": "spengler",
"email": "spengler@ghostbusters.example.com",
"image_24": "https://.../avatar/e3b51ca72dee4ef87916ae2b9240df50.jpg",
"image_32": "https://.../avatar/e3b51ca72dee4ef87916ae2b9240df50.jpg",
"image_48": "https://.../avatar/e3b51ca72dee4ef87916ae2b9240df50.jpg",
"image_72": "https://.../avatar/e3b51ca72dee4ef87916ae2b9240df50.jpg",
"image_192": "https://.../avatar/e3b51ca72dee4ef87916ae2b9240df50.jpg",
"image_512": "https://.../avatar/e3b51ca72dee4ef87916ae2b9240df50.jpg",
"team": "T012AB3C4"
},
"is_admin": true,
"is_owner": false,
"is_primary_owner": false,
"is_restricted": false,
"is_ultra_restricted": false,
"is_bot": false,
"updated": 1502138686,
"is_app_user": false,
"has_2fa": false
}
]
}
With dlt
You can use dlt to build a Slack to BigQuery pipeline in just a few seconds with a single command. Seriously, it is that simple. In preparation, let’s make sure to install what we need:
pip install dlt
pip install prefect
Then just run a simple init command:
dlt init slack bigquery
In the .dlt/secrets.toml file, enter your Slack and BigQuery credentials:
[sources.slack]
access_token="*****"
[destinations.bigquery]
location = "US"
[destination.bigquery.credentials]
project_id = "*****"
private_key = "*****"
client_email = "*****"
With a single command + adding some credentials, we now have the framework of a pipeline! Look at what has been generated, with a couple of small customizations:
Note that we are redacting some of the code in the preview for brevity, to follow along completely navigate to the repo.
# Pipeline to load Slack into BigQuery
from typing import List
import dlt
import pendulum
from slack import slack_source
def load_channels() -> None:
"""Execute a pipeline that will load a list of all the Slack channels in the workspace to BigQuery"""
# ...
def get_resources() -> List[str]:
"""Fetch a list of available dlt resources so we can fetch them one at a time"""
# ...
def load_channel_history(channel: str, start_date: Date) -> None:
"""Execute a pipeline that will load the given Slack channel incrementally beginning at the given start date."""
# ...
def get_users() -> None:
"""Execute a pipeline that will load Slack users list."""
# ...
if __name__ == "__main__":
channels = None
start_date = pendulum.now().subtract(days=1).date()
load_channels()
resources = get_resources()
for resource in resources:
if channels is not None and resource not in channels:
continue
load_channel_history(resource, start_date=start_date)
get_users()
What if it fails?
Great, we’ve got a pipeline that moves data from Slack to BigQuery, and we didn’t have to format any JSON - that alone is a win. However, there may be some issues. What if Slack rate limits you? What if BigQuery is down (😅)? What about a networking issue? What if the execution environment where this script lives isn’t working?
These questions are the difference between a pipeline and a resilient pipeline. They’re the difference between you getting sleep at night and you looking like a hero (or a dummy) to your stakeholders.
Adding Prefect
Prefect is a workflow orchestration tool for turning your pipelines into scheduled, repeatable, and resilient workflows. With Prefect you get scheduling, observability, and automations that can make sure your pipelines aren’t causing you stress in the middle of the night.
Make sure you’re logged in to Prefect Cloud by signing up and using the following command:
prefect cloud login
Luckily, Prefect is also incredibly Pythonic. Turning any pipeline into an observable, scheduled
Prefect flow is as simple as adding decorators to your functions and serving it up.
Here’s our dlt generated pipeline, scheduled daily:
from typing import List
import dlt
import pendulum
from prefect import flow, task
from slack import slack_source
@task
def load_channels() -> None:
...
@task
def get_resources() -> List[str]:
...
@task
def load_channel_history(channel: str, start_date: pendulum.Date) -> None:
...
@task
def get_users() -> None:
...
@flow
def slack_pipeline(
channels=None, start_date=pendulum.now().subtract(days=1).date()
) -> None:
load_channels()
resources = get_resources()
for resource in resources:
if channels is not None and resource not in channels:
continue
load_channel_history(resource, start_date=start_date)
get_users()
if __name__ == "__main__":
slack_pipeline.serve("slack_pipeline", cron="0 0 * * *")
We’ve added @task to our individual functions.
These will be treated as individual units of work by Prefect when they are executed.
We decorate our primary function (slack_pipeline) with @flow, which references
our task functions. We will schedule and kick off flows, which in turn will
execute tasks based on the decorators within them.
Finally, adding .serve to our if __name__ == "__main__": call means that a Prefect
deployment will be automatically created and scheduled to run daily at noon. We can
see our deployment and scheduled runs in the Prefect UI, and we’ll know when it ran or,
more importantly, if they didn't. We can further extend our pipeline by:
- Setting up remote infrastructure with workers
- Adding automations to notify us when the pipeline has failed
- Setting up retries
Where to handle failure
There are many levels of failure, you could say, from "accidentally liking your ex's social media post from five years ago" to "trying to assemble IKEA furniture without instructions," up to "asking for the Wi-Fi password at a funeral." So which ones should we handle where, and what are some quick solutions?
With dlt, your pipelines are resilient at the API level. From schema changes to network issues or memory overflow, there is automated resiliency and recovery that is specific to working with the pesky APIs of your tools.
With Prefect, your pipelines become resilient at the function level. If your workflows never run, break and fail, or break and never end, Prefect will be your backstop - notifying you and taking the appropriate action in case of failure.
Building resilient pipelines faster with dlt + Prefect
Getting into production is hard. First you need to build your pipeline, and then you need to make it resilient. With this tutorial, we’ve shown you how to quickly build pipelines with dlt and then turn that pipeline into a resilient, repeatable workflow with Prefect.
Prefect makes complex workflows simpler, not harder. Try Prefect Cloud for free for yourself, download our open source package, join our Slack community, or talk to one of our engineers to learn more.